SubAgent Is All You Need —— 效果好且廉价
不是让主 Agent 变得更强,而是让主 Agent 更克制。多 Agent 协作正在从可选技巧变成默认架构,用极少量顶级推理换来接近顶配质量、更高吞吐和大幅成本下降。
这两周我们在 auto-coder.chat 上做了一件看起来有点反直觉的事:
不是让主 Agent 变得更强,而是让主 Agent 更克制。
具体做法是新增了一条 Rule:
- 主 Agent 只负责理解需求、拆分任务、验收结果。
- 主 Agent 模型使用
Opus4.6或GPT5.4。 - 真正干活的执行层全部交给 Subagent。
- Subagent 模型统一使用
doubao-seed-2.0-pro。 - 主 Agent 被限制为只能通过调用 Subagent 完成任务。
听起来像是给顶级模型"降权",但结果恰恰说明: 多 Agent 协作正在从"可选技巧",变成"默认架构"。
为什么要这么设计?
过去很多团队做 AI 编程有一个默认思路: "既然最强模型最聪明,那就让它从头到尾都做。"
这个思路没错,但成本高,吞吐也有限。尤其当任务稍微复杂一点,主 Agent 既要思考又要执行,还要处理中间细节,很容易把高价值推理能力消耗在低价值操作上。
我们的目标很简单:
- 把贵模型的使用量压到最低。
- 保留关键决策质量。
- 利用 Subagent 做单任务内部并行,提升总体速度。
你可以把它理解成一个团队协作模型:
- 主 Agent 是 Tech Lead,负责方向、拆解、质量标准。
- Subagent 是执行工程师,专注把分配到的子任务快速完成。
在这个模型里,Opus4.6 不再承担全部劳动,而是像"稀土材料":
关键、稀缺、昂贵,但只用在最该用的地方。
我们怎么验证这套方案?
为了避免"体感优化",我们固定了一套验证流程:
- 每次需求完成后,立即提交一个 Commit。
- 使用 Cursor +
GPT5.4 ultra high执行 Review。 - 记录质量、速度、以及成本表现。
- 对比三种模式:
- 全程
Opus4.6 - 全程
doubao-seed-2.0-pro Opus/GPT主 Agent +doubaoSubagent(本次新 Rule)
- 全程
这一步很关键,因为很多"看起来更快"的方案,本质是把质量问题延迟到了后面。 我们希望每个需求都在同一套审查标准下被衡量,而不是只看任务是否"跑完"。
当前结果:轻微损耗,巨大收益
到目前为止,这套主从分层架构给出了非常清晰的结果:
- 相比"全程
Opus4.6",只有轻微效果损耗。 - 相比"全程
doubao-seed-2.0-pro",获得了巨大质量提升。 - 速度上有明显提升,尤其体现在单任务内部并行。
- 总体成本显著下降,单次需求压到几毛钱级别。
如果用一句话总结就是:
我们用极少量顶级推理,换来了接近顶配质量 + 明显更高吞吐 + 大幅成本下降。
这意味着什么?
意味着这不再是"大厂才用得起"的 AI 编程方式。 对普通团队、独立开发者、外包团队来说,这个成本带已经进入"可日常化使用"的区间。
这张图在讲什么?
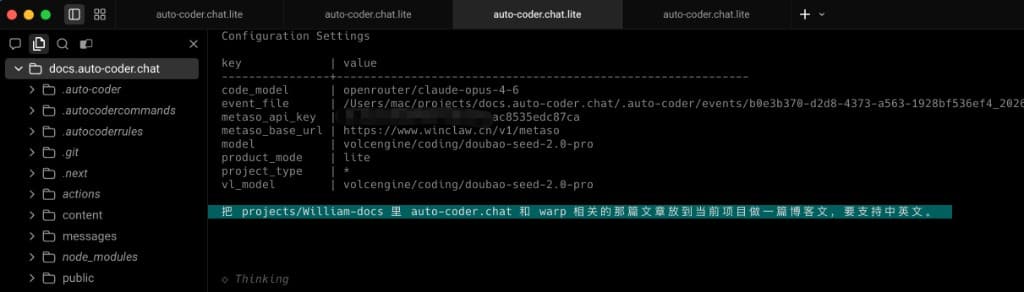
你现在看到的这张图,就是一次真实需求从起点开始的工作截面。 它不仅展示了主 Agent 的调度过程,还给了我们三条非常关键的"可观察证据":
- 主/子模型分工是明确配置的:图里的
code_model是主模型配置(我们用Opus4.6),model是 Subagent 模型配置(我们用doubao-seed-2.0-pro)。 - 主 Agent 会主动做高质量拆分:它准确识别出两个可探索角度,而不是把任务粗暴丢给单个执行链路。
- 执行模式是并行而不是串行:多个 Subagent 同时推进,直接缩短探索时间,并提高覆盖完整度。
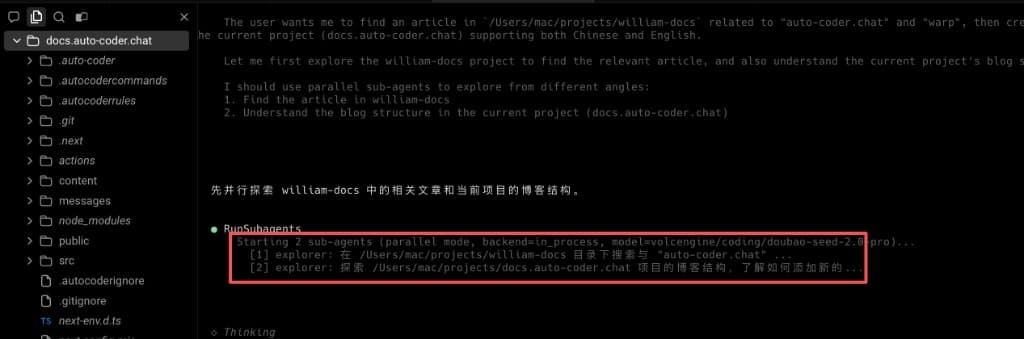
也就是说,这里并不是"多开两个线程"这么简单,而是"强模型做判断,性价比模型做并行执行"的工程化协作。 继续看下一张图,你会发现这种并行不是一次性的技巧,而是可复用的工作模式:
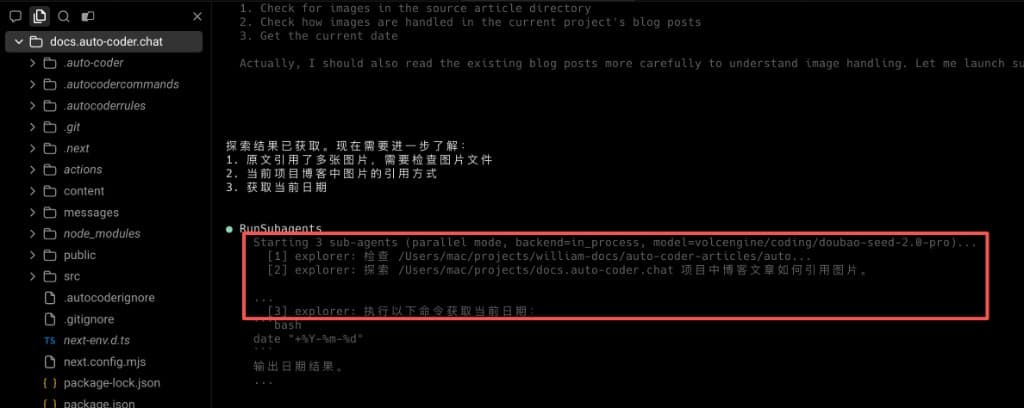
这次主 Agent 一次性启动了 3 个并行 Subagent,覆盖了三类不同任务:
- 检查来源文章目录中的图片资源。
- 分析目标项目里博客图片的引用方式。
- 直接执行命令获取当前日期(
date)。
这说明主 Agent 不只是"会拆任务",而是已经具备"按任务类型选择执行器"的调度能力:信息探索、结构分析、命令执行可以同时推进。 对真实开发流程来说,这种混合并行会显著减少等待链路,让结果更快收敛,也更不容易漏项。
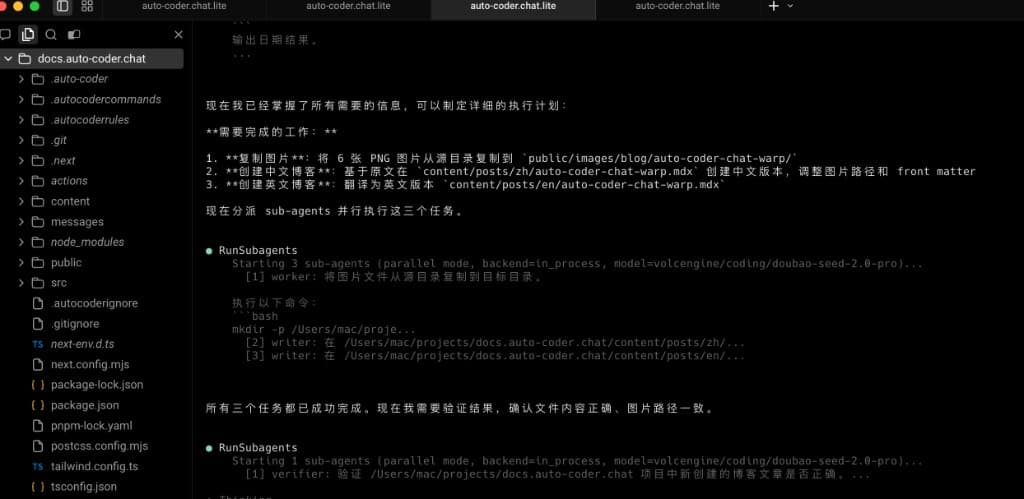
再看这一张图,流程已经从"探索阶段并行"进入了"执行阶段并行":
- 主 Agent 明确了 3 项落地任务(资源复制、中文版本创建、英文版本创建)。
- 3 个 Subagent 并行写入不同目标路径,直接推进交付产物生成。
- 执行完成后,主 Agent 立即追加了 verifier 子任务做结果核验。
这一步非常关键:并行不是为了"跑得快就结束",而是"快产出 + 快验证"组合。 也正因为有这层回收与验证,整个流程才能在提速的同时维持稳定质量。
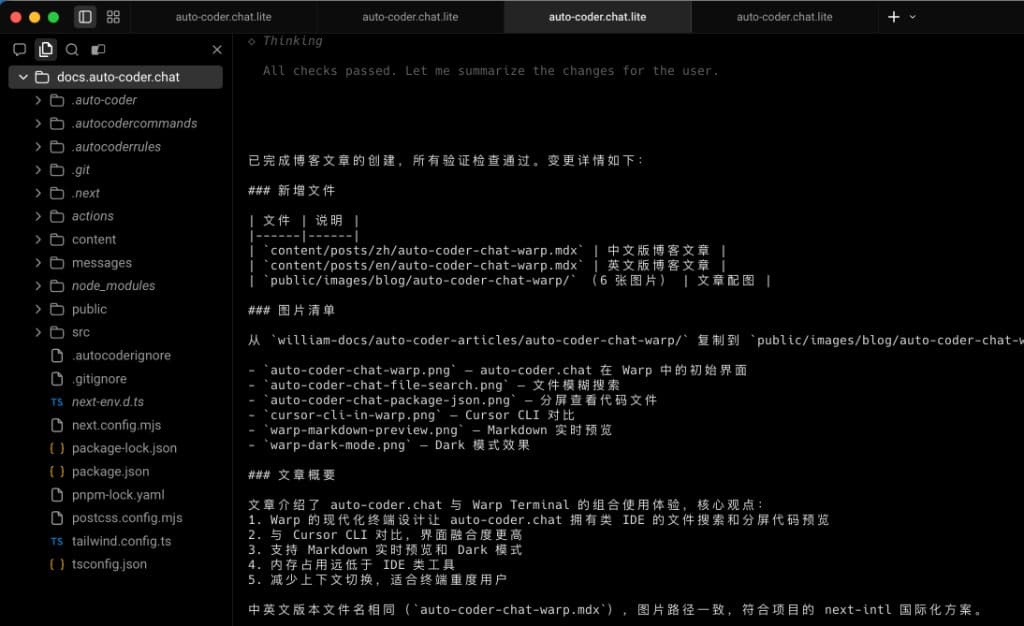
这张图展示了流程的最后一公里:主 Agent 将执行结果汇总为结构化交付清单,并明确给出核验结论(checks passed)。
从画面里可以看到,它会把关键结果逐项列清:
- 新增了哪些文件(例如中英文文章文件、图片目录)。
- 图片资源从哪里复制到哪里。
- 文章核心内容覆盖了哪些要点。
- 中英文版本的命名与路径是否一致。
这意味着 Subagent 架构的价值不只在"做得快",还在"可审计": 每一步都有证据、每个产物可追溯,主 Agent 最终给出的不是一句"完成了",而是一份可被人类快速复核的交付摘要。
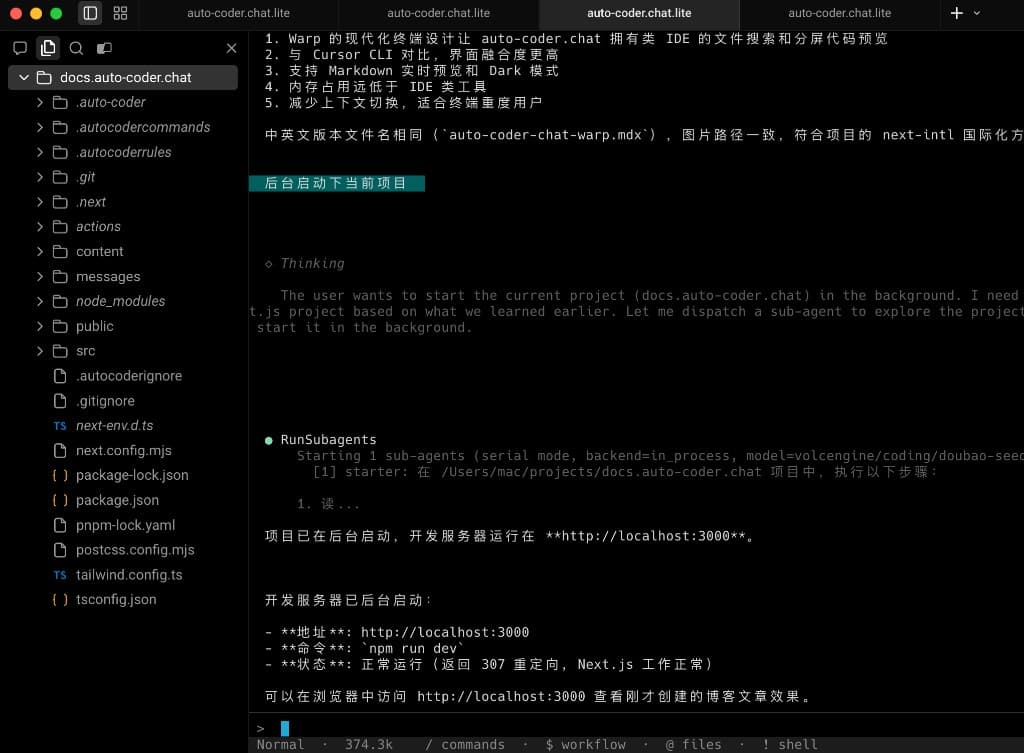
到这里,流程还没有结束。
这张图体现的是"交付后验证"环节:主 Agent 在总结完成后,继续调度 subagent 启动当前项目的开发服务,并返回可访问地址(如 http://localhost:3000)与运行状态。
这一步把"代码产出"延伸为"可运行结果确认":
- 不只验证文件存在,还验证项目是否能正常启动。
- 给出明确访问入口,便于人类立即抽样检查页面效果。
- 把"写完代码"升级为"可用交付"的最后一跳。
因此整条链路是完整的: 并行探索 → 并行执行 → 回收核验 → 结构化总结 → 运行态验证。 这也是 Subagent 模式相较单 Agent 串行流程最有工程价值的地方。
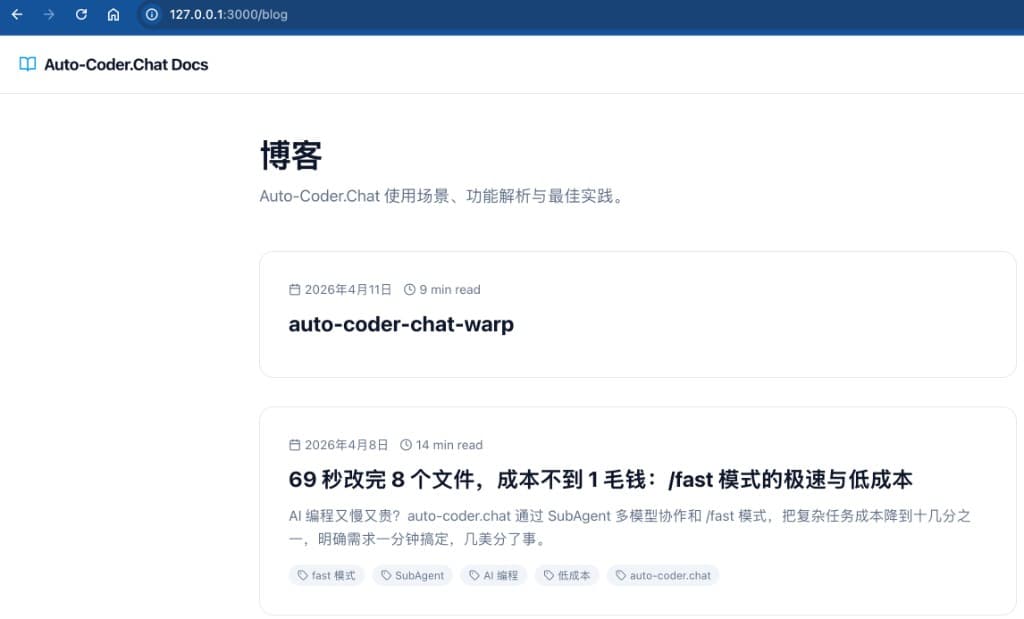
最后这张图把"运行态验证"再往前推了一步: 不仅服务可启动,而且目标文章已经在博客列表中被正确渲染和展示。
这意味着验证从"技术成功"走向"业务可见":
- 开发服务状态正常(页面可访问)。
- 内容产物已进入目标信息架构(博客列表)。
- 人类可以直接在前端界面完成最终验收,而不必只看终端日志。
到这里,这次需求就形成了一个真正可复用的端到端模板: 需求输入 → 主 Agent 拆分 → Subagent 并行执行 → 自动核验 → 页面可见性确认。
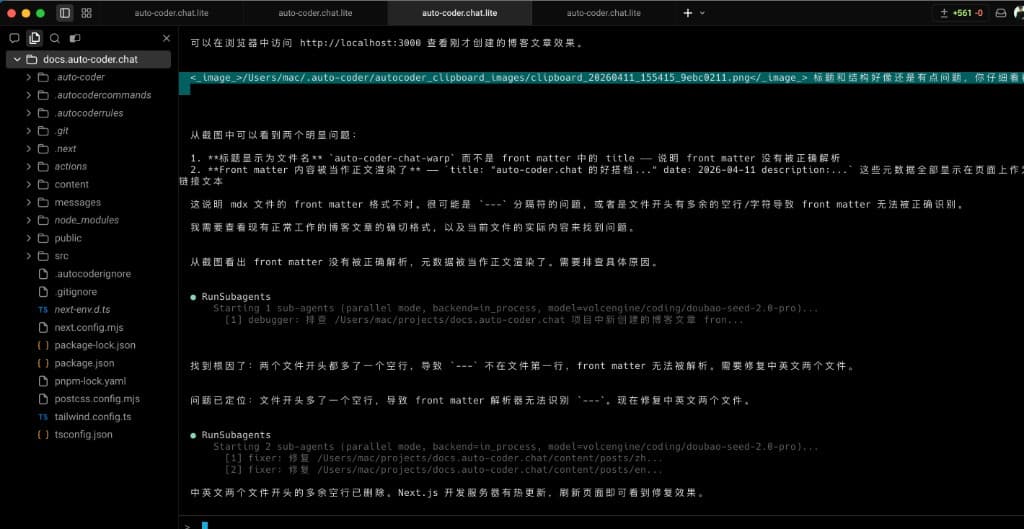
而且这套模式在"线上修错"场景里同样稳定。 这张图里,主 Agent 发现页面标题异常后,没有进入低效试错,而是快速发起 3 次 subagent 调用完成闭环:
- debugger:定位根因(front matter 解析异常,文件头存在多余空行)。
- fixer:并行修复中英文两个目标文件。
- verifier:确认修复后页面与内容恢复正常。
修复结果可以直接在页面中看到:标题与内容恢复正确,渲染正常。 这就是 Subagent 架构的另一个现实价值:把故障修复从"十几轮对话反复试探"压缩成"几次有分工的调用"。
以这次为例,主模型通过 3 次 subagent 调用就解决了问题。 如果不采用 subagent,通常会走成串行试错,速度更慢,调用轮次可能上升到十几轮,最终带来更高时间成本和模型费用。
Subagent 时代,不是替代,而是分层
很多人期待"模型价格总会降下来",到时候就不需要这些分层技巧了。 但这个假设忽略了一个基本现实:好模型必然是贵的,模型价格不会无限下降。
原因很简单——推理能力越强的模型,训练和推理成本越高,这是底层算力决定的经济规律。即使每一代模型的性价比在提升,顶级模型和中等模型之间永远存在显著价差。就像芯片制程一直在进步,但最先进的制程永远是最贵的。
所以真正的问题从来不是"等模型便宜",而是: 如何在当前价格结构下,用最少的顶级推理换取最大的工程产出?
Subagent 正是这个问题的答案。它不是替代,而是分层:
- 顶级模型负责高价值决策:理解需求、拆分任务、验收质量。用量极少,但每一次调用都在关键路径上。
- 中成本模型承担高频执行:文件操作、代码生成、信息检索。用量大,但单价低,且可并行。
- Review 模型负责统一质量门槛:独立于执行链路,确保产出不滑坡。
这三层一旦打通,带来的不只是成本优化,还有速度的显著提升——因为 Subagent 天然支持单任务内部并行,多个子任务同时推进,总耗时被压缩到最长子任务的长度,而不是所有子任务的累加。
AI 编程就会从"单体 Agent 的偶发高光",走向"工程化的稳定产能"。
而这,就是 Subagent 时代真正要来的原因。
如何开启 Subagent 模式?
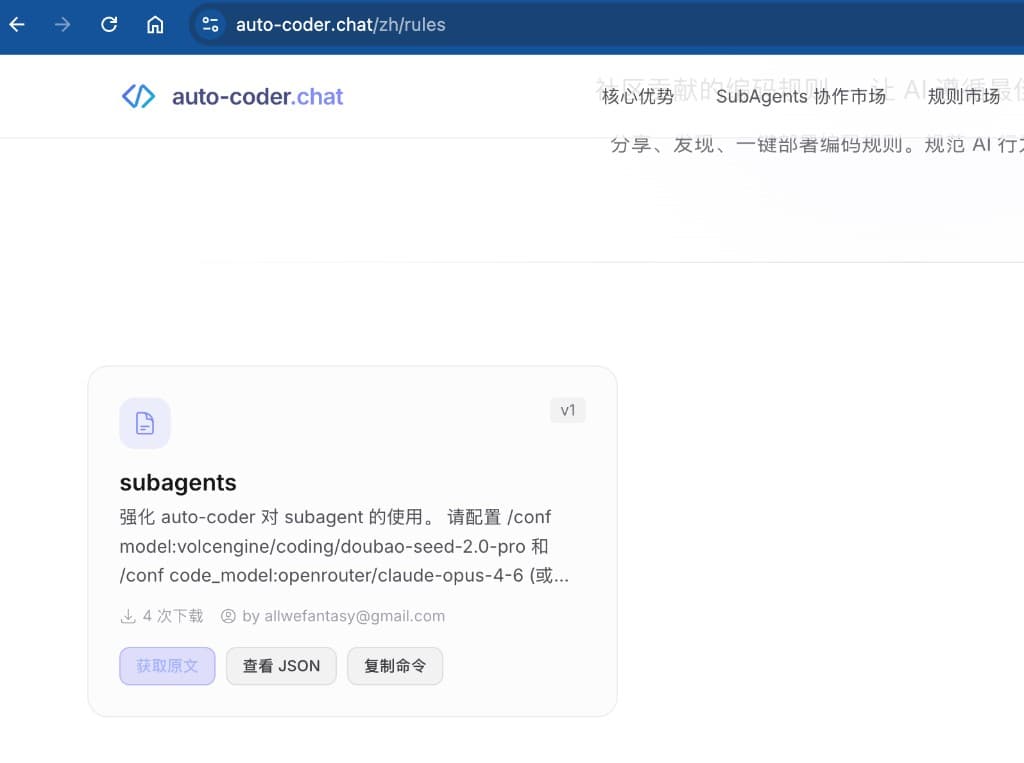
开启方式非常简单,三步搞定:
- 访问 auto-coder.chat,在规则市场找到
subagentsRule。 - 点击"复制命令",获取安装指令。
- 在命令行中粘贴运行,Rule 即刻生效。
生效后,auto-coder.chat 会自动按照 Rule 中的配置,将主 Agent 限制为只通过 Subagent 完成任务,无需额外修改代码或手动调整流程。
[[auto-coder.chat:auto-coder.chat