SubAgent Is All You Need — Better Results, Lower Cost
Instead of making the main Agent stronger, we made it more restrained. Multi-agent collaboration is shifting from an optional technique to a default architecture — achieving near-top-tier quality with minimal premium inference, higher throughput, and dramatically lower costs.
Over the past two weeks, we did something counterintuitive with auto-coder.chat:
Instead of making the main Agent stronger, we made it more restrained.
Specifically, we added a new Rule:
- The main Agent only handles understanding requirements, splitting tasks, and reviewing results.
- The main Agent model uses
Opus4.6orGPT5.4. - All actual execution is delegated to Subagents.
- Subagent models uniformly use
doubao-seed-2.0-pro. - The main Agent is restricted to completing tasks only through Subagent calls.
It sounds like "demoting" the top-tier model, but the results prove otherwise: Multi-agent collaboration is shifting from an "optional technique" to a "default architecture."
Why This Design?
Many teams have a default approach to AI coding: "Since the strongest model is the smartest, just let it do everything end to end."
This approach isn't wrong, but it's expensive and throughput-limited. Especially when tasks get slightly complex — the main Agent has to think, execute, and handle intermediate details simultaneously, easily wasting high-value reasoning capacity on low-value operations.
Our goals were simple:
- Minimize expensive model usage.
- Preserve critical decision quality.
- Leverage Subagents for intra-task parallelism to boost overall speed.
Think of it as a team collaboration model:
- The main Agent is the Tech Lead — responsible for direction, decomposition, and quality standards.
- Subagents are execution engineers — focused on completing assigned subtasks quickly.
In this model, Opus4.6 no longer carries the entire workload. Instead, it's like "rare earth materials":
Critical, scarce, expensive — but used only where it matters most.
How We Validated This Approach
To avoid "feel-good optimization," we established a fixed validation process:
- After each requirement is completed, immediately submit a Commit.
- Use Cursor +
GPT5.4 ultra highto perform a Review. - Record quality, speed, and cost metrics.
- Compare three modes:
- Full
Opus4.6 - Full
doubao-seed-2.0-pro Opus/GPTmain Agent +doubaoSubagent (the new Rule)
- Full
This step is crucial because many "seemingly faster" approaches simply defer quality issues to later stages. We wanted every requirement measured against the same review standards, not just whether the task "finished running."
Current Results: Minimal Loss, Massive Gains
So far, this primary-secondary layered architecture has delivered very clear results:
- Compared to "full
Opus4.6": only slight quality degradation. - Compared to "full
doubao-seed-2.0-pro": massive quality improvement. - Noticeable speed improvements, especially in intra-task parallelism.
- Significant overall cost reduction, with per-requirement costs dropping to a few cents.
In one sentence:
We traded minimal top-tier inference for near-top-tier quality + noticeably higher throughput + dramatically lower costs.
What does this mean?
It means this is no longer an AI coding approach "only big companies can afford." For regular teams, independent developers, and outsourcing teams, this cost range has entered the "daily-usable" zone.
What Are These Screenshots Showing?
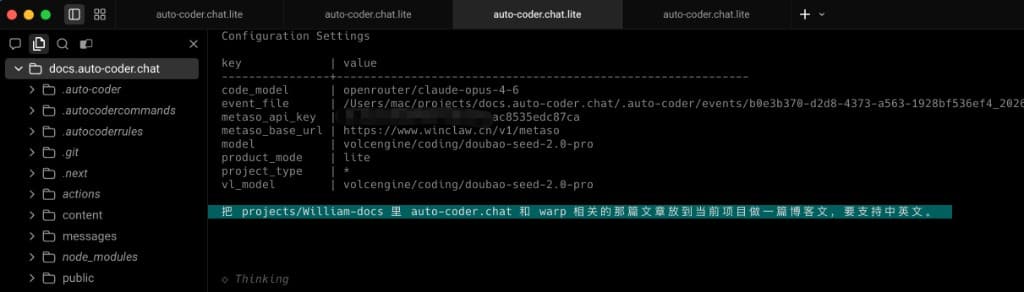
This screenshot shows a real requirement's workflow from the starting point. It not only demonstrates the main Agent's orchestration process but provides three critical pieces of "observable evidence":
- Primary/secondary model roles are explicitly configured: The
code_modelin the image is the main model config (we useOpus4.6), andmodelis the Subagent model config (we usedoubao-seed-2.0-pro). - The main Agent proactively performs high-quality decomposition: It accurately identifies two exploration angles rather than crudely dumping the task into a single execution chain.
- Execution mode is parallel, not serial: Multiple Subagents push forward simultaneously, directly shortening exploration time and improving coverage completeness.
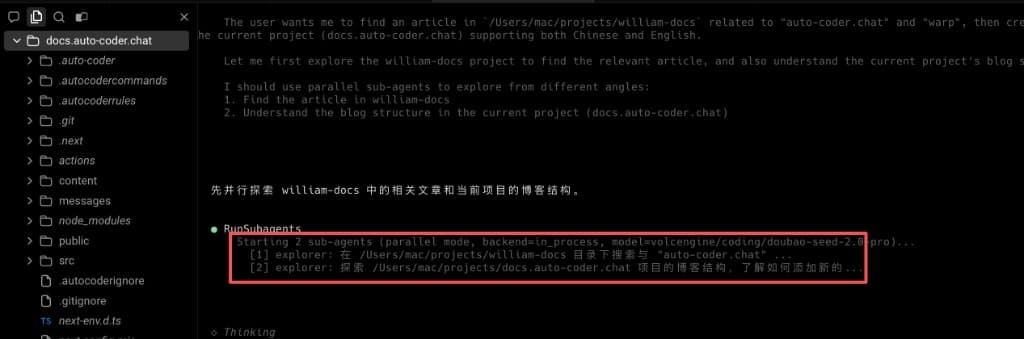
This isn't simply "opening two extra threads" — it's engineered collaboration where "the strong model makes judgments, and cost-effective models execute in parallel." The next screenshot shows that this parallelism isn't a one-time trick but a reusable work pattern:
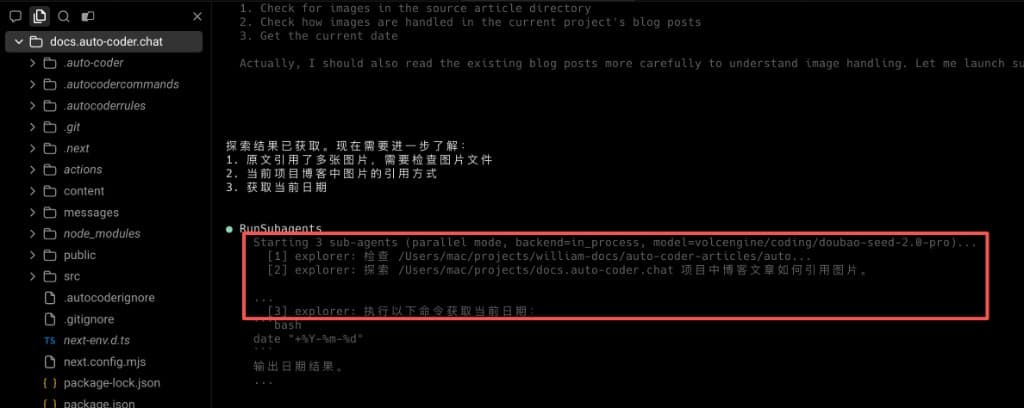
This time the main Agent launched 3 parallel Subagents covering three different task types:
- Check image resources in the source article directory.
- Analyze how the target project references blog images.
- Execute a command to get the current date (
date).
This shows the main Agent doesn't just "know how to split tasks" — it already has the dispatching capability to "select executors by task type": information exploration, structural analysis, and command execution can all proceed simultaneously. For real development workflows, this mixed parallelism significantly reduces waiting chains, converges results faster, and makes it harder to miss items.
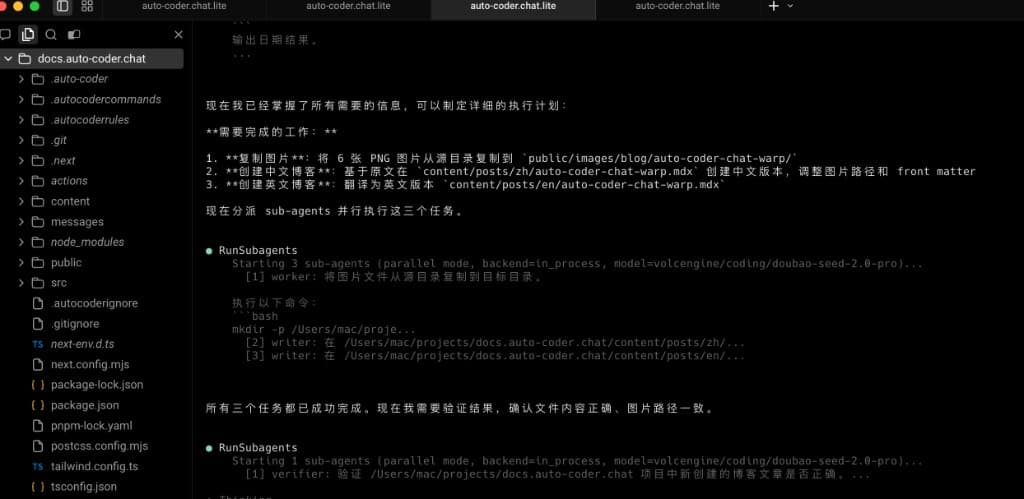
In this screenshot, the flow has moved from "exploration-phase parallelism" to "execution-phase parallelism":
- The main Agent identified 3 concrete tasks (resource copying, Chinese version creation, English version creation).
- 3 Subagents write to different target paths in parallel, directly pushing deliverable generation forward.
- After execution completes, the main Agent immediately dispatches a verifier subtask for result validation.
This step is critical: parallelism isn't about "finishing fast and stopping" — it's the "fast output + fast verification" combination. It's precisely because of this collection and verification layer that the entire flow maintains stable quality while accelerating.
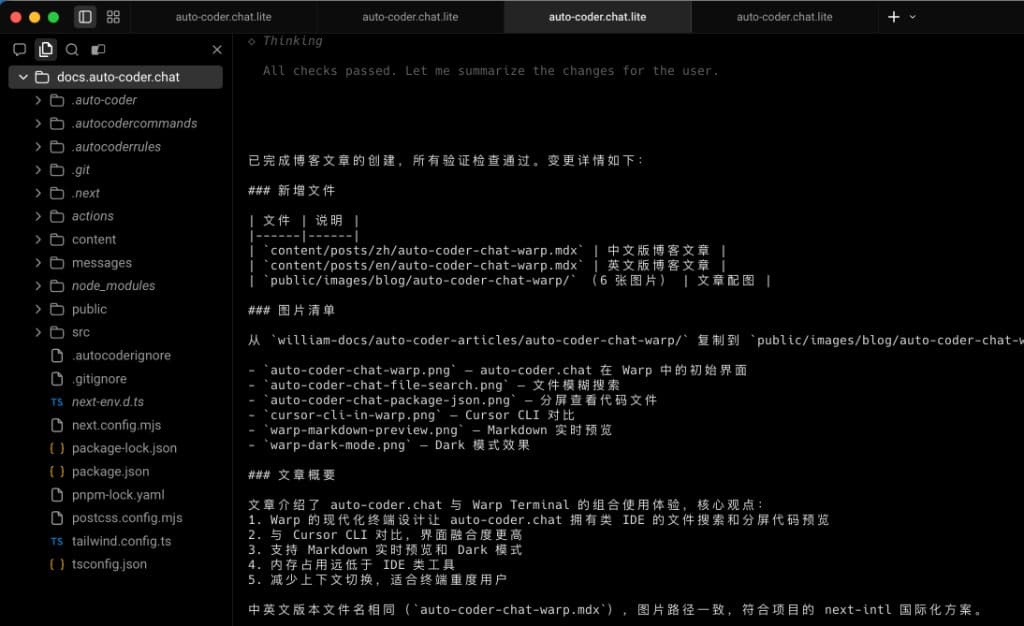
This screenshot shows the last mile: the main Agent consolidates execution results into a structured delivery checklist and explicitly provides validation conclusions (checks passed).
You can see it itemizes key results:
- What files were added (e.g., bilingual article files, image directories).
- Where image resources were copied from and to.
- What key points the article content covers.
- Whether bilingual version naming and paths are consistent.
This means the SubAgent architecture's value isn't just in "doing it fast" but in "auditability": Every step has evidence, every deliverable is traceable. The main Agent doesn't just say "done" — it produces a delivery summary that humans can quickly review.
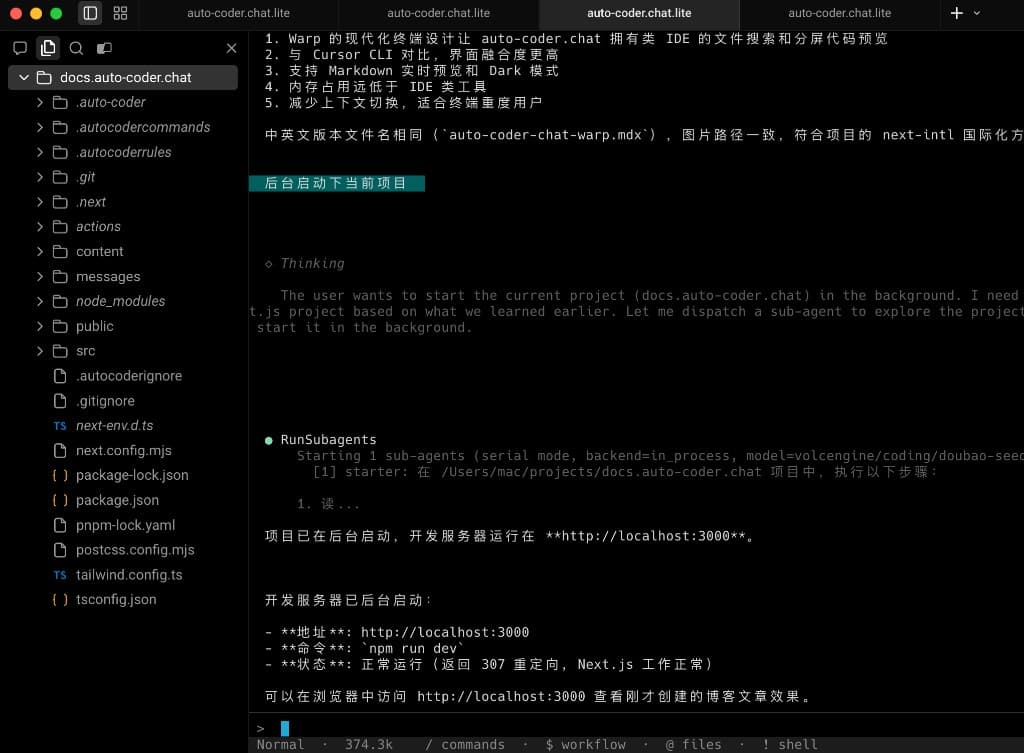
The flow doesn't end here.
This screenshot shows the "post-delivery verification" phase: after summarizing, the main Agent continues to orchestrate a subagent to start the project's development server and return the accessible URL (e.g., http://localhost:3000) along with running status.
This step extends "code output" to "runnable result confirmation":
- Verifying not just that files exist, but that the project starts normally.
- Providing a clear access point for humans to immediately spot-check page results.
- Upgrading "code written" to the final hop of "usable delivery."
The complete chain is: Parallel exploration → Parallel execution → Collection & verification → Structured summary → Runtime verification. This is also where the SubAgent pattern provides the most engineering value compared to single-Agent serial flows.
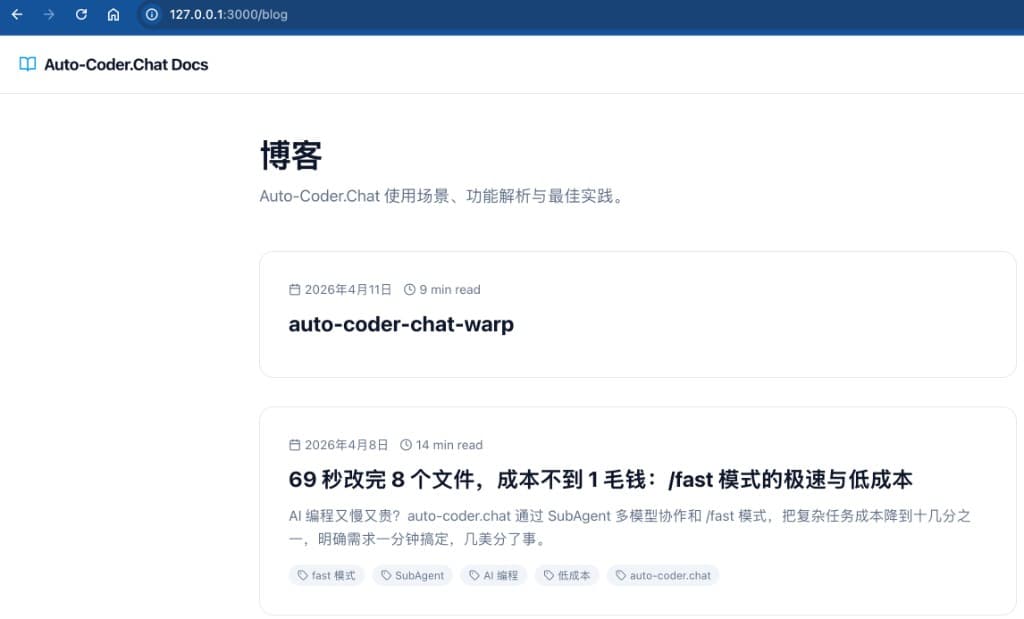
This final screenshot pushes "runtime verification" one step further: Not only is the service startable, but the target article is correctly rendered and displayed in the blog listing.
This means verification moves from "technical success" to "business visibility":
- Development service status is normal (page accessible).
- Content deliverables have entered the target information architecture (blog listing).
- Humans can complete final acceptance directly in the frontend interface, without relying solely on terminal logs.
At this point, this requirement forms a truly reusable end-to-end template: Requirement input → Main Agent decomposition → Subagent parallel execution → Auto verification → Page visibility confirmation.
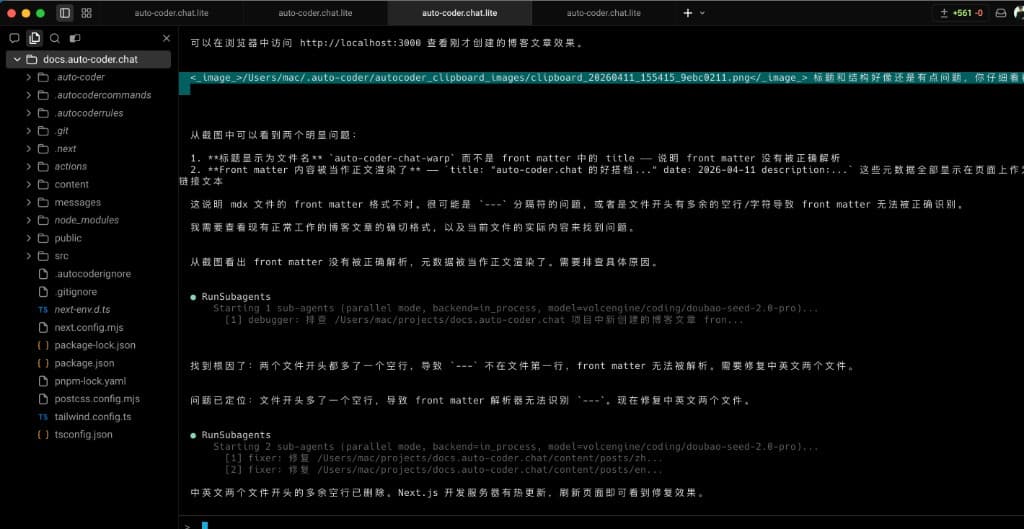
Moreover, this pattern is equally stable in "live bug fix" scenarios. In this screenshot, after the main Agent discovered abnormal page titles, instead of entering inefficient trial-and-error, it quickly initiated 3 subagent calls to close the loop:
- debugger: Locate the root cause (front matter parsing anomaly, extra blank line at file header).
- fixer: Fix both Chinese and English target files in parallel.
- verifier: Confirm the page and content are restored after the fix.
The fix results are directly visible on the page: title and content restored correctly, rendering normally. This is another practical value of the SubAgent architecture: compressing fault repair from "a dozen rounds of back-and-forth trial and error" into "a few organized calls with clear division of labor".
In this case, the main model resolved the issue with just 3 subagent calls. Without subagents, it would typically follow serial trial-and-error, slower speed, potentially escalating to over a dozen rounds, ultimately incurring higher time costs and model fees.
The SubAgent Era: Not Replacement, But Layering
Many people expect "model prices will eventually come down," and then these layering techniques won't be needed. But this assumption ignores a fundamental reality: Good models will always be expensive. Model prices won't drop indefinitely.
The reason is simple — the stronger a model's reasoning capabilities, the higher its training and inference costs. This is an economic law dictated by underlying compute. Even as each generation of models improves in cost-effectiveness, there will always be a significant price gap between top-tier and mid-tier models. Just like chip manufacturing processes keep advancing, but the most advanced process is always the most expensive.
So the real question has never been "wait for models to get cheaper," but rather: How to achieve maximum engineering output with minimum top-tier inference under the current pricing structure?
SubAgent is the answer to this question. It's not replacement — it's layering:
- Top-tier models handle high-value decisions: Understanding requirements, splitting tasks, reviewing quality. Minimal usage, but every call is on the critical path.
- Mid-cost models handle high-frequency execution: File operations, code generation, information retrieval. High volume but low unit cost, and parallelizable.
- Review models maintain unified quality gates: Independent of the execution chain, ensuring output doesn't degrade.
Once these three layers are connected, the benefits go beyond cost optimization to include significant speed improvements — because Subagents naturally support intra-task parallelism. Multiple subtasks progress simultaneously, compressing total time to the duration of the longest subtask rather than the sum of all subtasks.
AI coding will evolve from "sporadic brilliance of a monolithic Agent" to "engineered, stable productivity."
And that's the real reason the SubAgent era is coming.
How to Enable SubAgent Mode?
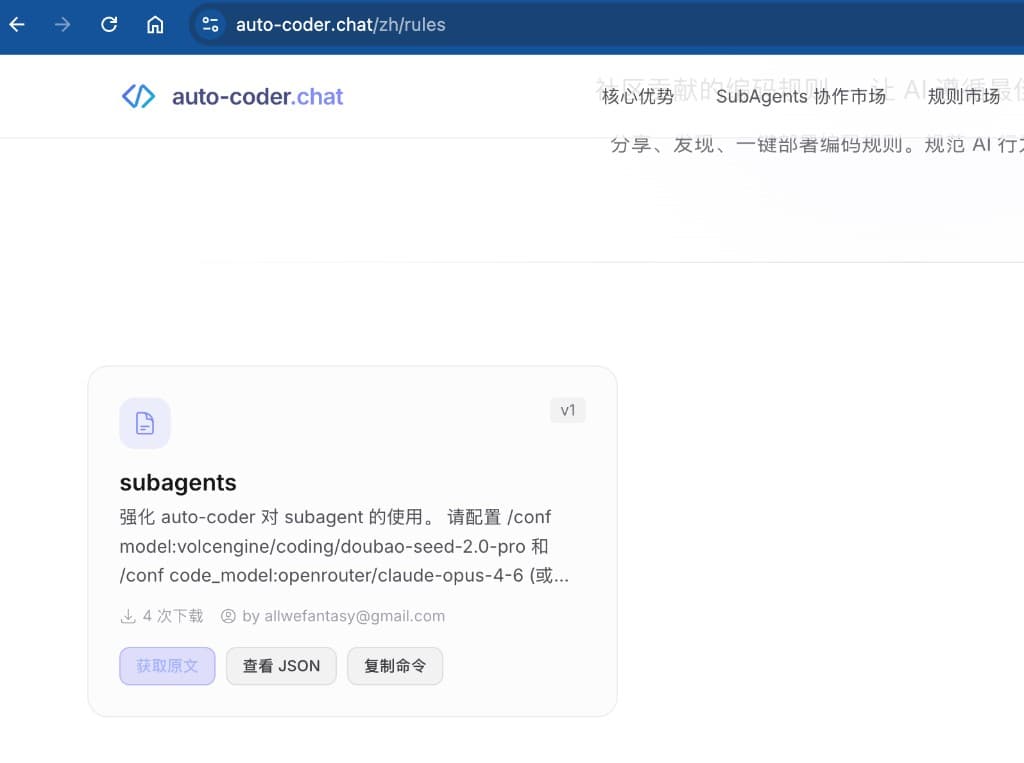
Enabling it is very simple — three steps:
- Visit auto-coder.chat and find the
subagentsRule in the rules marketplace. - Click "Copy Command" to get the installation command.
- Paste and run it in your terminal — the Rule takes effect immediately.
Once active, auto-coder.chat will automatically follow the Rule's configuration, restricting the main Agent to complete tasks only through Subagents. No additional code changes or manual process adjustments needed.
[auto-coder.chat: auto-coder.chat